

GPGPU Benchmark



This benchmark panel, which can be launched from Tools | GPGPU Benchmark, offers a set of OpenCL GPGPU benchmarks. These are designed to measure GPGPU computing performance using various OpenCL workloads. Each individual benchmark can be run on up to 16 GPUs, including AMD, Intel and NVIDIA GPUs, or the combination of these. Of course, CrossFire and SLI configurations as well as both dGPUs and APUs are fully supported. Currently, there is only preliminary support for HSA configurations. Basically, any computing device that is listed as a GPU among the OpenCL devices will be benchmarked.
Current OpenCL benchmarks are not optimized for any GPU architecture. Instead, the AIDA64 OpenCL module relies on the OpenCL compiler which optimizes the OpenCL kernel to run best on the underlying hardware. The OpenCL kernels used for these benchmarks are compiled in real-time, using the GPU's OpenCL driver. Because of this, it is always recommended to have all video drivers (Catalyst, ForceWare, HD Graphics, etc.) updated to their latest version. For the compilation, the following OpenCL compiler options are passed: -cl-fast-relaxed-math -cl-mad-enable.
For comparison purposes, the GPGPU Benchmark Panel offers CPU measurements as well. However, the CPU benchmarks do not use OpenCL, but are written in native x86/x64 machine code, utilizing available instruction set extensions such as SSE, AVX, AVX2, FMA and XOP. These CPU benchmarks are very similar to the old AIDA64 CPU and FPU benchmarks, but this time they measure maximum computing performance (FLOPS, IOPS). The CPU benchmarks are heavily multi-threaded, and are optimized for each CPU architecture introduced since the first Pentium.
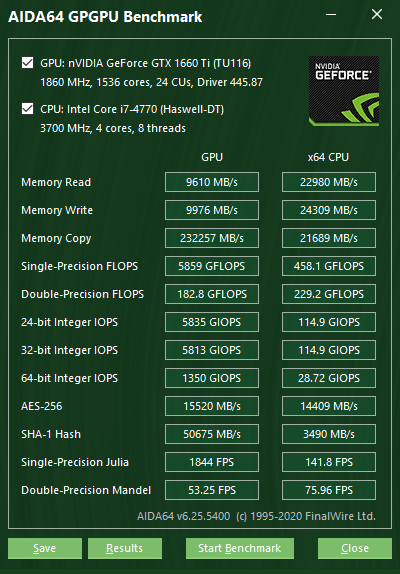
Currently, the following benchmark tests are available:
Memory Read
Measures the bandwidth between the GPU device and the CPU, effectively measuring the performance the GPU can copy data from its own device memory into the system memory. It is also called Device-to-Host Bandwidth. The CPU benchmark measures memory read bandwidth, that is, how fast the CPU can read data from the system memory.
Memory Write
Measures the bandwidth between the CPU and the GPU device, effectively measuring the performance the GPU can copy data from the system memory into its own device memory. It is also called Host-to-Device Bandwidth. The CPU benchmark measures memory write bandwidth, that is, how fast the CPU can write data into the system memory.
Memory Copy
Measures the performance of the GPU's own device memory, effectively measuring the performance the GPU can copy data from its own device memory to another place in the same device memory. It is also called Device-to-Device Bandwidth. The CPU benchmark measures memory copy bandwidth, that is, how fast the CPU can move data in the system memory from one place to another.
Single-Precision FLOPS
Measures the MAD (Multiply-Addition) performance of the GPU, otherwise known as FLOPS (Floating-Point Operations Per Second), with single-precision (32-bit, "float") floating-point data.
Double-Precision FLOPS
Measures the MAD (Multiply-Addition) performance of the GPU, otherwise known as FLOPS (Floating-Point Operations Per Second), with double-precision (64-bit, "double") floating-point data. Not all GPUs support double-precision floating-point operations. For example, current Intel desktop and mobile graphics devices only support single-precision floating-point operations.
24-bit Integer IOPS
Measures the MAD (Multiply-Addition) performance of the GPU, otherwise known as IOPS (Integer Operations Per Second), with 24-bit integer ("int24") data. This special data type is defined in OpenCL, given that many GPUs are capable of executing int24 operations in their floating-point units, effectively increasing integer performance by a factor of 3 to 5 when compared to 32-bit integer operations.
32-bit Integer IOPS
Measures the MAD (Multiply-Addition) performance of the GPU, otherwise known as IOPS (Integer Operations Per Second), with 32-bit integer ("int") data.
64-bit Integer IOPS
Measures the MAD (Multiply-Addition) performance of the GPU, otherwise known as IOPS (Integer Operations Per Second), with 64-bit integer ("long") data. Most GPUs do not have dedicated execution resources for 64-bit integer operations. Such devices emulate 64-bit integer operations on their 32-bit integer execution units. In such cases, 64-bit integer performance can be very low.
AES-256
We can use this OpenCL-based GPGPU benchmark to measure the AES-256 encryption performance of modern graphics processors and APUs.
SHA-1
We can use this OpenCL-based GPGPU benchmark to measure the SHA-1 hashing performance of modern graphics processors and APUs.
Single-Precision Julia
Measures single-precision (32-bit, “float”) floating-point performance through the computation of several frames of the popular “Julia” fractal.
Double-Precision Mandel
Measures double-precision (64-bit, “double”) floating-point performance through the computation of several frames of the popular “Mandelbrot” fractal. Not all GPUs support double-precision floating-point operations. For example, current Intel desktop and mobile graphics devices only support single-precision floating-point operations.
User interface
You can use the checkboxes to select a GPU device or the CPU for the benchmarks. The state of the CPU checkbox will be stored after closing the panel.
You can launch the benchmarks for the selected devices by clicking the “Start Benchmark” button. If you want to run all benchmarks, but only on the GPU(s), you need to double-click the GPU column label. If you only want to run the Memory Read benchmarks on both the GPU(s) and the CPU, you need to double-click the Memory Read label. If you only want to run the Memory Read benchmark on only the GPU(s), you need to double-click the cell where the requested benchmark result will appear when the benchmark is completed.
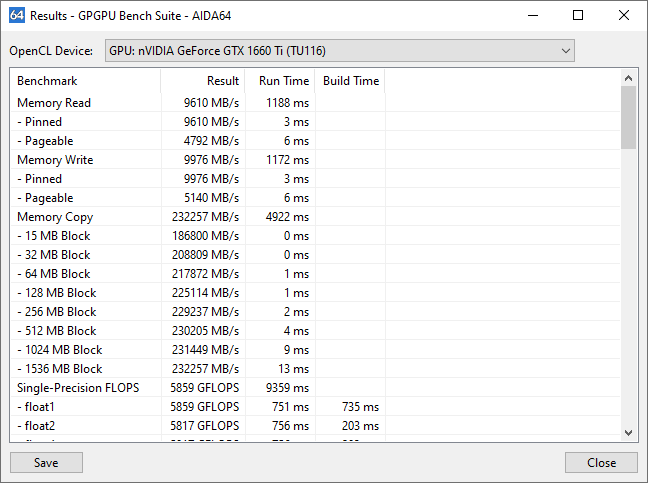
The benchmarks are executed simultaneously on all selected GPUs, using multiple threads and multiple OpenCL context, each with a single command queue. CPU benchmarks, however, are only launched when the GPU benchmarks are completed. It is currently not possible to run the GPU and CPU benchmarks simultaneously.
If there are multiple GPUs in the system, the first result column will display an aggregated score for all GPUs. Individual GPU results are combined (added up), and the column label will look like e.g. “4 GPUs”. If you want to check individual results, you can either check only one GPU or click the Results button to open the results window.
If you happen to have two GPU devices, and you disable the CPU test by unchecking its checkbox, the panel will switch to dual-GPU mode where the first column is used for displaying results for GPU1, and the second for GPU2. If you want to see the combined performance of both GPUs, just check the CPU checkbox again after the benchmark has been completed, and the interface will switch back to the default layout.