

Benchmark




AIDA64 offers dedicated microbenchmarks, which are available under the Benchmark category in the Page menu. These are synthetic benchmarks, which means that they can be used to measure the theoretical maximum performance of the system. Memory bandwidth, CPU and FPU benchmarks are built on the multi-threaded AIDA64 benchmark engine that – since AIDA64 Business v4.00 – supports up to 640 simultaneous processing threads and 10 processor groups.
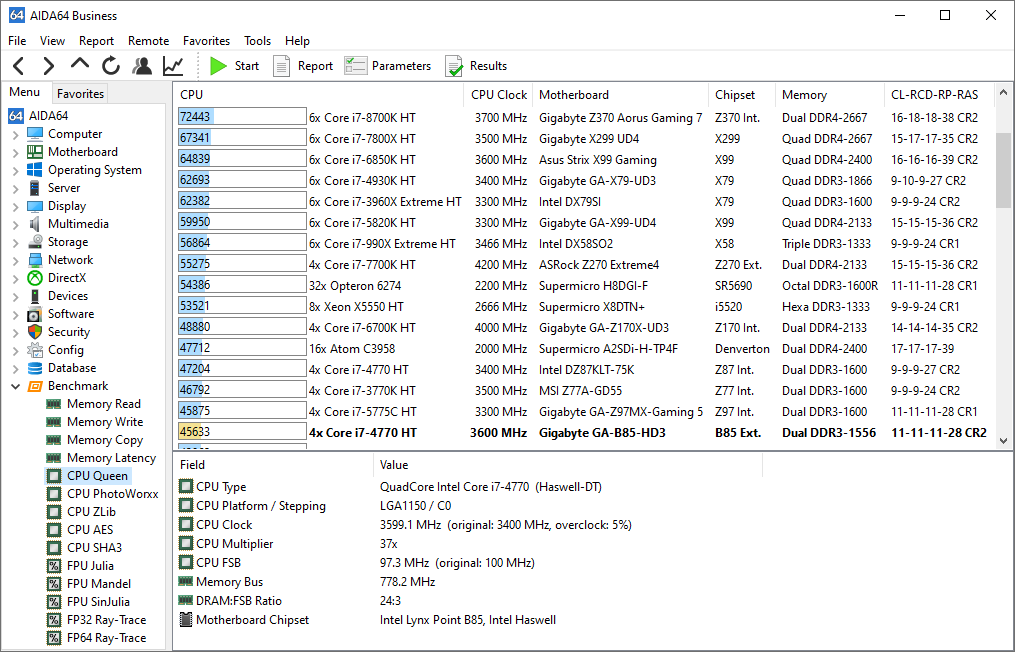
Thanks to AIDA64's huge reference result database, benchmark results can be compared to those of other configurations. By clicking the “Results” button on the toolbar, we can save and manage our benchmark results, and we can also hide reference results and user results, which are listed on the results page by default.
Memory read, write, copy and latency
Memory benchmarks measure the maximum bandwidth achievable when performing the selected operations (read, write, copy). The memory latency benchmark measures the time it takes for data to arrive in the integer registers of the CPU after the issue of the read command.
CPU Queen
This simple integer benchmark focuses on the CPU's branch prediction capabilities and branch misprediction penalties. It calculates solutions for the classic “N queens puzzle” on a 10x10 chessboard.
CPU PhotoWorxx
This integer benchmark measure CPU performance with several 2D photo processing algorithms. The test mainly stresses the SIMD integer arithmetic execution units of the CPU and the memory subsystem.
CPU ZLib
This integer benchmark measures combined CPU and memory subsystem performance using the public ZLib compression library.
CPU AES
This integer benchmark measures CPU performance using AES (Advanced Encryption Standard) data encryption.
CPU Hash
This integer benchmark measures CPU performance using the SHA1 hashing algorithm.
FPU VP8
This benchmark measures video compression performance using version 1.1.0 of the Google VP8 (WebM) video codec.
FPU Julia
This benchmark measures the single precision (or 32-bit) floating-point performance through the computation of several “Julia” fractal frames.
FPU Mandel
This benchmark measures the double precision (or 64-bit) floating-point performance through the computation of several “Mandelbrot” fractal frames.
FPU SinJulia
This benchmark measures the extended precision (or 80-bit) floating-point performance through the computation of a single frame of a modified “Julia” fractal.
FP32 Ray-Trace
This benchmark measures the single precision (also known as 32-bit) floating-point performance through the computation of a scene with a SIMD-enhanced ray tracing engine.
FP64 Ray-Trace
This benchmark measures the double precision (also known as 64-bit) floating-point performance through the computation of a scene with a SIMD-enhanced ray tracing engine.